(1)기본 메커니즘
NL 조인을 효과적으로 수행하려면 조인 컬럼에 인덱스가 필요합니다. 만약 적절한 인덱스가 없다면 Inner 테이블을 탐색할 때마다 반복적으로 Full Scan을 수행하므로 비효율적입니다. 그럴때 옵티마이저는 소트머지 조인이나 해시조인을 고려하게 됩니다.
의미는 두 테이블을 각각 정렬한 다음에 두 집합을 머지(merge)하면서 조인을 수행합니다. 아래 두 단계로 진행됩니다.
1.소트단계 : 양쪽 집합을 조인 컬럼 기준으로 정렬합니다.
2.머지단계: 정렬된 양쪽 집합을 서로 머지(merge)합니다.
소트머지 조인은 outer루프와 inner루프가 Sort Area에 미리 정렬해 둔 자료구조를 이용한다는 점만 다르고 실제 조인 오퍼레이션을 수행하는 과정은 NL조인과 다르지 않습니다. NL조인과 마찬가지로 outer조인할 때 순서가 고정됩니다.
Sort Area는 PGA영역에 할당되므로 SGA를 경유해 인덱스와 테이블을 액세스할 때보다 훨씬 빠릅니다. PGA는 프로세스만을 위한 독립적인 메모리 공간이기 때문에 데이터를 읽을 때 래치 획득과정이 필요없습니다.
소트머지조인은 use_merge힌트를 가지고 유도할 수 있습니다.
select /*+ ordered use_merge(e) */ *
from dept d, emp e
where d.deptno = e.deptno
위의 쿼리는 dept테이블(ordered힌트 때문에 from 절 순서대로 조인하여야함)을 기준으로 emp 테이블과 조인할 때 소트머지 조인을 사용하라고 지시하고 있습니다.
이때의 처리과정은 다음과 같습니다.
1.Outer테이블인 dept를 deptno를 기준으로 정렬
2.Inner테이블인 emp를 deptno 기준으로 정렬
3.Sort Area에 정렬된 dept테이블을 스캔하면서 정렬된 emp테이블과 조인
아래 그림은 3번의 처리과정을 표현한 것입니다.
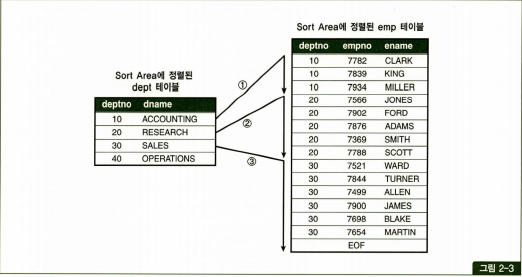
주목한 점은 emp테이블이 정렬돼 있기 때문에 조인에 실패하는 레코드를 만나는 순간 멈출 수 있다는 사실입니다.
(deptno가 10인 레코드를 찾다가 20을 만나는순간 멈추는 것)
또 한가지는 정렬된 emp에서 스캔 시작점을 찾으려고 매번 탐색하지 않아도 된다는 점입니다.
(deptno가 20인 레코드를 찾는 스캔을하기위해서 10번부터 찾지않고 스캔하다가 멈춘지점부터 수행)
Outer 테이블인 dept도 같은 순서로 정렬돼 있기 때문에 가능합니다.
만약 M:M 조인은 어떨까요?
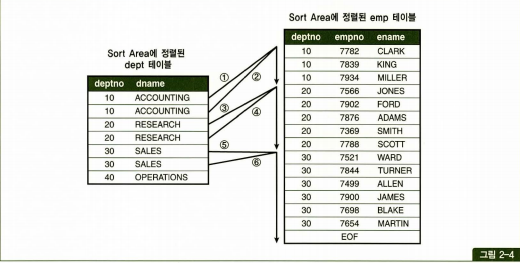
두 가지 방법을 생각해 볼 수 있는데, 시작점을 찾으려고 하면 매번 이진(binary)탐색을 수행하는 방식과 변수를 하나 더 선언해 앞에서 스캔했던 시작점까지 기억해 두는 방식입니다. 두개 중 어느것이 맞다고 할 수는 없지만 소트머지조인 시 Outer테이블까지 정렬한다는 사실을 통해 후자일 것이라고 추측할 수는 있습니다.
(2)소트머지조인의 특징
소트머지조인은 조인을 위해 실시간으로 인덱스를 생성하는 것과 다름없습니다.(실제 오브젝트를 만들지는 않습니다.)
양쪽 집합을 정렬한 다음 NL조인과 같은 방식으로 진행하지만 PGA영역에 저장된 데이터를 이용하기 때문에 빠릅니다.
따라서 소트 부하만 감수한다면, 건건이 버퍼캐시를 거치면서 조인하는 NL조인보다 유리하다고 할 수 있습니다. (하지만 오라클 버전이 높아질 수록 NL조인 시 버퍼캐시에서 같은 블록을 반복적으로 액세스할 때 발생하는 비효율을 없애려고 버퍼 피닝(buffer pinning)기능이 확대되고 있어 시간이 지날수록 NL조인이 유리해지고 있습니다.)
NL조인은 조인 컬럼에 대한 인덱스 유무에 따라 크게 영향을 받지만 소트머지조인은 영향을 받지 않습니다.
그리고 양쪽 집합을 개별적으로 읽고 나서 조인한다는 것도 특징입니다. 따라서 조인 컬럼에 인덱스가 없는 상황에서 두 테이블을 독립적으로 읽어 조인 대상 집합을 줄일 수 있을 때 아주 유리하다고 할 수 있습니다.
스캔 위주의 액세스 방식을 사용한다는 점도 소트 머지 조인의 중요한 특징입니다. 하지만 모든 처리가 스캔방식으로 이루어 지는 것은 아니며 양쪽 소스 집합에서 정렬 대상 레코드를 찾는 작업만큼은 인덱스를 이용해 Random 액세스 방식으로 처리될 수 있고, 그때 발생하는 Random 액세스량이 많다면 소트머지조인의 이점이 사라질 수도 있습니다. 이는 해시조인도 마찬가지입니다.
select /*+ use_merge(d e) */ *
from dept d,emp e
where d.deptno=e.deptno
and d.loc = 'CHICAGO'
and e.job = 'SALESMAN'
위의 쿼리에서 loc='CHICAGO',job='SALESMAN'이 두 조건에 해당하는 레코드를 찾을 때는 인덱스를 이용할 수 있습니다.
아래와 같은 상황에서는 소트머지 조인이 유용합니다.
- First(Outer)테이블에 소트 연산을 대체할 인덱스가 있을 때
- 조인할 First(Outer)집합이 이미 정렬돼 있을 때
-조인 조건식이 등치(=)조건이 아닐 때
위의 상황이외에는 해시조인이 같은 상황에서 성능이 더 좋다고 할 수 있습니다.
(3)First(Outer)테이블에 소트 연산을 대체할 인덱스가 있을 때
소트머지조인은 무조건 전체범위처리 방식이라고 알려졌지만 항상그렇지는 않습니다. 해시 조인과 마찬가지로 한쪽집합(Inner, Second테이블)은 전체범위를 처리하고 다른한쪽(Outer,First테이블)은 일부만 읽고 멈추도록 할 수 있습니다. Outer(First)테이블 조인 컬럼에 인덱스가 있을 때 그렇습니다. 만약 그렇게 처리할 수 있으면 OLTP성 업무에서 소량의 테이블과 대량의 테이블을 조인할 때 소트 머지 조인을 유용하게 사용할 수 있습니다.
그리고 인덱스를 이용해 소트연산을 대체할 수 있는 대상은 First 테이블에만 국한된다는 사실입니다.


인덱스를 두개 만들고 위의 쿼리를 수행하면 Outer(first)테이블에서는 인덱스가 이미 정렬돼있기 때문(loc,deptno)에 Sort Join오퍼레이션을 수행하지 않지만, 같은 원리이지만 Inner(Second)테이블은 Sort Join 오퍼레이션을 수행하는것을 볼 수 있습니다.
위 실행계획에 표시된 순서상 dept가 First테이블이고 emp가 Second테이블이지만 항상 First테이블을 먼저 읽는 것은 아닙니다. First테이블은 이미 정렬된 인덱스를 사용할 것이므로 그대로 두고, Second집합인 emp테이블을 읽어 정렬한 결과를 Sort Area에 담습니다. 조인 연산을 진행할 때는 dept_idx인덱스부터 읽기 시작합니다.
(4)조인할 First(Outer)집합이 이미 정럴돼 있을 때
Group by,order by, distinct 연산 등을 먼저 수행한 경우인데, 그때는 조인을 위해 다시 정렬하지 않아도 되므로 소트머지 조인이 유리한 경우입니다.
이 경우에도 First 집합이 정렬돼 있을 때만 소트 연산이 생략되며, Second 집합은 설사 정렬돼 있더라도 Sort Join 오퍼레이션을 수행합니다.
(5)조인 조건식이 등치(=)조건이 아닐 때
해시 조인은 조인 조건식이 등치조건일 때만 사용할 수 있지만 소트머지조인은 등치조건이 아닐 때도(between,<,>,<= ,>=)사용할 수 있습니다.
'스터디 > 오라클 성능고도화 원리와 해법2' 카테고리의 다른 글
| CH02. 조인 원리와 활용 - 04.조인 순서의중요성 (0) | 2020.06.02 |
|---|---|
| CH02. 조인 원리와 활용 - 03.해시조인 (0) | 2020.05.28 |
| CH02. 조인 원리와 활용 - 01. Nested Loops 조인 (5) | 2020.04.12 |
| CH01. 인덱스 원리와 활용 - 09. 비트맵 인덱스 (0) | 2020.03.26 |
| CH01. 인덱스 원리와 활용 - 08. 인덱스 설계 (0) | 2020.03.08 |



댓글