인덱스는 키 값에 해당하는 테이블 레코드를 찾아갈 수 있도록 주소 정보를 제공합니다. 일반적으로 사용되는 B*Tree 인덱스는 테이블 레코드를 가리키는 rowid 목록을 키 값과 함께 저장하는 구조입니다.
테이블에 100개 레코드가 있으면 인덱스에도 100개 rowid를 키 값과 함께 저장합니다. rowid에는 중복 값이 없지만 키에는 중복 값이 있을 수 있습니다. 개념적으로 비트맵 인덱스는 키 값에 중복이 없고, 키 값 별로 하나의 비트맵 레코드를 갖습니다. 그리고 비트맵 상의 각 비트가 하나의 테이블 레코드와 매핑됩니다. 비트가 1로 설정돼 있으면 상응하는 테이블 레코드가 해당 키 값을 포함하고 있음을 의미합니다.
(1)기본구조
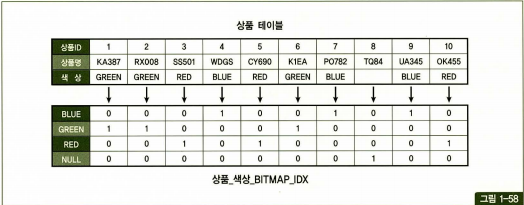
그림의 아래쪽이 색상 컬럼이 생성한 비트맵 인덱스를 표현한 것인데, 키 값이 BLUE인 첫번째 행을보면 4번째 7번째 9번째 비트가 1로 설정되어 있습니다. 따라서 상응하는 테이블 레코드의 색상이 BLUES 임을 확인할 수 있습니다.
블록 덤프를 통해 실제 비트맵 인덱스 내부 구조를 살펴보면 아래와 같습니다.

마지막 컬럼(col3)은 시작 rowid와 종료 rowid 구간에 속한 테이블 레코드와 매핑되는 비트맵입니다. 첫 번째 비트는 시작 rowid(col 1)가 가리키는 레코드와 매핑되고, 마지막 비트는 종료 rowid(col 2)가 가리키는 레코드와 매핑됩니다.

비트맵 인덱스는 이처럼 첫 번째와 마지막 비트의 rowid만을 갖고 있다가 테이블 액세스가 필요할 때면 각 비트가 첫 번째 비트로부터 떨어져 있는 상대적인 거리를 이용해 rowid 값을 환산합니다.
비트맵 위치와 rowid 매핑
데이터 블록은 한 익스텐트 내에서 연속된 상태로 저장되지만 익스텐트끼리는 서로 인접해 있지 않습니다. 심지어 다른 데이터 파일에 흩어져 저장되는데 , 어떻게 시작 rowid와의 상대적인 거리로 정확한 레코드 위치를 알아낼 수 있을까요?
오라클이 한 블록에 저장할 수 있는 최대 레코드 개수를 제한한다는 데서 힌트를 얻을 수 있습니다. 오라클의 표준 블록크기는 8,192바이트이고 1바이트 크기의 레코드라면 한 블록에 수천 개를 저장할 수 있을거 같지만 실제 테스트해보면 730개를 넘지 못합니다. 크기를 5바이트로 늘려도 한 블록당 730개를 넘지 않습니다.
이것을 보면 오라클은 한 블록에 저장할 수 있는 최대 레코드 개수를 제한하고 있습니다.
예를 들어, 위의 상품 테이블에 총 20개 블록이 할당되었다고 하겠습니다. 첫 번째와 두 번째 익스텐트에 각각 10개 블록이 있고, 하나의 테이블 블록이 가질 수 있는 최대 레코드 개수는 730이라고 하겠습니다. 이 테이블 색상 컬럼에 비트맵 인덱스를 만들면 오라클은 네 개 (BLUE,GREEN,RED,NULL)의 키 값에 각각 14,600(=730*20)개 비트를 할당(초기값은 0)
하고 값에 따라 비트를 설정합니다. 첫 번째 키 값을 예로 들면 'BLUE'인 레코드에 해당하는 비트를 모두 1로 설정합니다.
비트맵 인덱스를 스캔하면서 테이블 레코드를 찾아갈 때는 어떤식으로 할까요? 예를 들어 9,500번째 비트가 1로 설정돼 있으면 14번째 블록 10번째 레코드를 찾아가면 됩니다. (9500/730 = 13.01... 이므로 14번째블록에서 mod(9500,760) = 10으로 10번째 레코드를 확인할 수 있습니다.
키 값의 수가 많을 때
비트맵 인덱스는 키 값별로 하나의 레코드를 갖는데, 저장할 키 값의 수가 많을 때는 한 블록에 모두 담지 못합니다. 비트맵을 저장하기 위해 두 개 이상 블록이 필요해지면 오라클은 B*Tree 인덱스 구조를 사용하며, 값의 수가 많을수록 인덱스 높이(height)도 증가합니다. 하지만 이런구조면 B*Tree인덱스보다 더 많은 공간을 차지할 수 있어 비트맵 인덱스로 부적합합니다.
키 값별로 로우 수가 많을 때
한 블록 크기의 비트맵으로 표현할 수 없을 정도로 테이블 로우 수가 많을 때도 두 개 이상 블록이 필요해집니다.
예를 들어, 'BLUE'값 하나에 대한 비트맵을 저장하기 위해 2+1/2 블록만큼의 공간을 필요로 한다면 아래와 같은 구조로 저장됩니다. 한 블록이 단 하나의 비트맵 레코드로 구성될 수 있지만 실제 테스트해 보면 ,한 블록에 적어도 2개 비트맵 레코드가 담기도록 잘라서 저장하는 것을 확인할 수 있습니다.

비트맵 압축
실제로 비트맵 인덱스는 여러가지 압축 알고리즘이 사용되기 때문에 서로 다른 rowid 범위를 갖습니다. 테이블 로우 수가 많고 키 값의 수도 많다면 완전히 0으로 채워진 비트맵 블록들이 생기는데, 오라클은 그런 블록들을 제거합니다. 비트맵 뒤쪽에 0이 반복되어도 이를 제거합니다. 그리고 앞, 뒤, 중간 어디든 같은 비트맵 문자열이 반복되면 checksum 비트를 두어 압축합니다. 이 때문에 각 비트맵이 가리키는 rowid 구간이 서로 달라지지만 시작 rowid와 종료 rowid만 알고 있으면 비트와 매핑되는 rowid를 계산하거나 다른 비트맵과 Bitwise 연산하는 데에는 전혀 지장이 없습니다.
(2) 비트맵 인덱스 활용
비트맵 인덱스는 성별처럼 Distinct Value 개수가 적을 때 저장효율이 매우 좋습니다. 그런 컬럼이라면 B*Tree 인덱스보다 훨씬 적은 용량을 차지하므로 인덱스가 여러 개 필요한 대용량 테이블에 유용합니다. Distinct Value 개수가 적은 컬럼일 때 저장효율이 좋지만 테이블 Random 액세스 발생 측면에서는 B8Tree 인덱스와 똑같기 때문에 그런 컬럼을 비트맵 인덱스로 검색하면 그다지 좋은 성능을 기대하기 어렵습니다. 스캔할 인덱스 블록이 줄어드는 정도의 성능 이점만 얻을 수 있습니다.
하나의 비트맵 인덱스 단독으로는 쓰임새가 별로 없지만 여러 비트맵 인덱스를 동시에 사용할 수 있다는 특징 때문에 대용량 데이터 검색 성능을 향상시키는 데에 큰 효과가 있습니다. 여러 개 비트맵 인덱스로 Bitwise 연산을 수행한 결과 테이블 액세스량이 크게 줄어든다면 극정인 성능 향상을 가져다 줍니다.
두 개 이상 비트맵을 이용한 AND 연산 뿐아니라 OR, NOT 연산도 가능합니다.
select * from 상품
where (크기 = 'SMALL' or 크기 is null)
and 색상 = 'GREEN'
위의 쿼리를 수행한다 할때 '크기' 컬럼 인덱스로부터 'SMALL'과 NULL에 대한 비트맵을 읽고, '색상' 인덱스로부터 'GREEN'에 대한 비트맵을 읽어 그림과 같이 놓고 Bitwise연산을 수행하여 조건절을 만족하는 레코드를 찾을 수 있습니다.
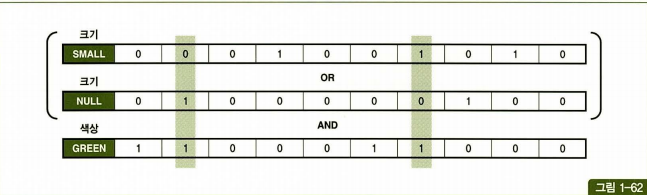
비트맵 인덱스를 이용하면 null 값에 대한 검색도 가능합니다.
비트맵 인덱스는 여러 인덱스를 동시에 활용할 수 있다는 장점 때문에 다양한 조건절이 사용되는 정형화되지 않은 임의 질의가 많은 환경에 적합합니다. 하지만 비트맵 인덱스는 lock에 의한 DML부하가 심한 것이 단점입니다. 레코드 하나만 변경되더라도 해당 비트맵 범위에 속한 모든 레코드에 lock이 걸립니다. OLTP성 환경에 비트맵 인덱스를 쓸 수 없는 이유가 이것입니다. 즉 읽기 위주의 대용량 DW환경에 적합합니다.
(3)RECORDS_PER_BLOCK
오라클은 한 블록에 저장할 수 있는 최대 레코드 개수를 제한한다고 했습니다. 그래야 비트맵 위치와 rowid를 매핑할 수 있기 때문입니다. 그런데 실제 블록에 저장되는 평균적인 레코드 개수는 여기에 한참 못미치므로(블록수 * 730) 비트맵 인덱스에 낭비되는 공간이 많이 생깁니다. 이에 오라클은 블록에 저장될 수 있는 최대 레코드 개수를 사용자가 지정할 수 있는 기능을 제공합니다.
alter table [테이블 명] minimize records_per_block;
주의할 것은 블록당 레코드 개수가 정상치보다 낮은 상태에서 minize records_per_block명령을 수행하지 말아야한다는 사실입니다. 그럴 경우, 추가로 데이터가 입력되면서 블록마다 공간이 많이 생기고, 비트맵 인덱스가 줄어드는 것 이상으로 테이블 크기가 커지는 결과가 나옵니다.
'스터디 > 오라클 성능고도화 원리와 해법2' 카테고리의 다른 글
| CH02. 조인 원리와 활용 - 02.소트 머지 조인 (0) | 2020.04.16 |
|---|---|
| CH02. 조인 원리와 활용 - 01. Nested Loops 조인 (5) | 2020.04.12 |
| CH01. 인덱스 원리와 활용 - 08. 인덱스 설계 (0) | 2020.03.08 |
| CH01. 인덱스 원리와 활용 - 07. 인덱스 스캔효율 (0) | 2020.03.05 |
| CH1. 인덱스 원리와 활용 - 06. IOT,클러스터 테이블 활용 (0) | 2020.03.01 |




댓글